
Elasticsearch & Generative AI: The Final Product and Beyond
The combination of Elasticsearch & Generative AI improves the customer experience, customer retention, and developer productivity by offering highly accurate and relevant search results in no time.
But what allows the integration of Elasticsearch & Generative AI, how does it work, and what steps do you need to execute?
You might be wondering about all the ins and outs of the stated surprising combo. Don’t stress out because this article covers all the related concepts in detail.
From explaining the RAG pattern, Elasticsearch Relevance Engine (ESRE), Elastic AI Assistant, Elastic Observability, and relevance ranking to showing how you can generate embeddings and configure the OpenAI and Azure OpenAI connectors, this post serves as a complete source of the information you’re looking for.
So, wait no more, and start reading to get rid of those confusing queries in your mind.
Generative AI Using RAG Pattern
When Generative AI uses the Retrieval Augmented Generation (RAG) pattern or architecture, the latter enhances the capabilities of the Generative AI models by adding an information retrieval system to them, states Microsoft. This system provides grounding data to the Gen AI models to generate more accurate, specific, and reliable responses instead of generic answers to your queries.
Thus, implementing the RAG pattern gives you sufficient control over the grounding data used by the Gen AI models to generate responses. Please refer to the following diagram to see the conceptual flow of using RAG with LLMs.
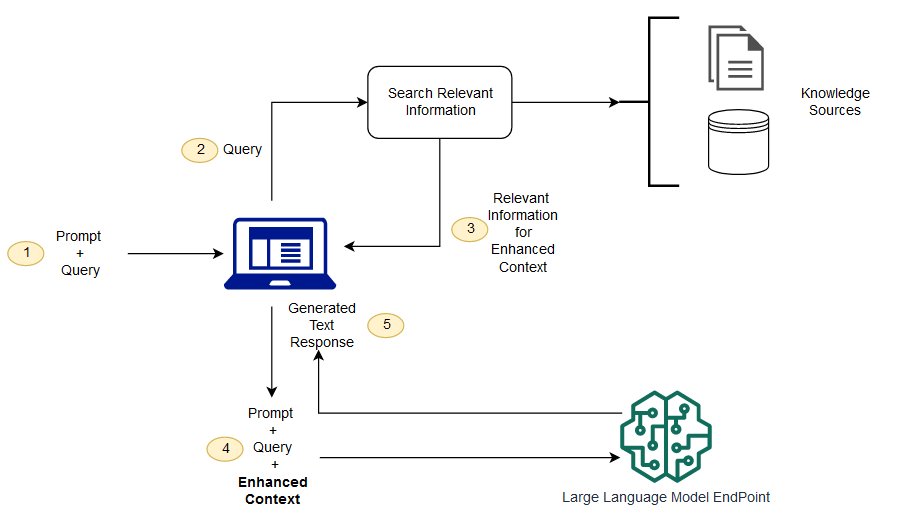
Source Credit: AWS
Furthermore, consider this example by AWS. You want a Large Language Model (LLM) to provide you with the latest information. In this case, you can use the RAG pattern, and provide the latest statistics, research, or news to the LLM or simply connect the LLM to news sites, live social media feeds, or other frequently updated information sources to achieve your updated results.
Here is another scenario discussed by Microsoft. Say that you want a Large Language Model (LLM) to give you highly accurate responses based on your enterprise content. By using the RAG pattern, you can feed the LLM your enterprise content through vectorized documents, images, etc.
Now, upon entering a query, you’ll receive the response based on the fed content. That’s how it works. Please refer to the next section to see how this pattern is implemented in Elasticsearch.
How Does Vector Database Fit in Elasticsearch?
Vector database fits in Elasticsearch through Elasticsearch Relevance Engine (ESRE), resulting in the development of Elastic AI Assistant. ESRE brings new capabilities to create highly relevant AI search applications. It blends the best of AI with Elastic’s text search, offering a complete suite of advanced retrieval algorithms and the ability to integrate with LLMs.
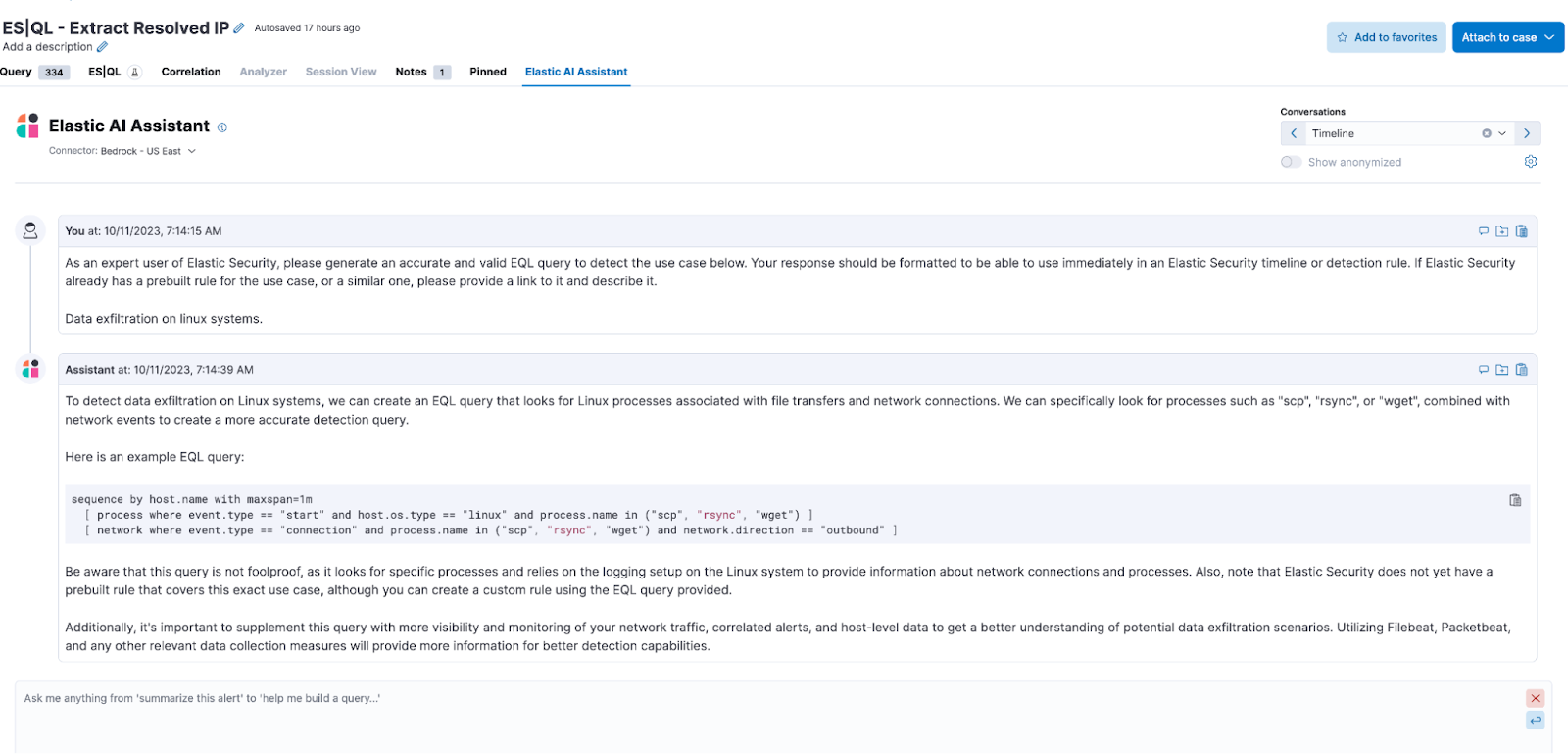
Source Credit: Elastic.co
Here are the benefits of the ESRE-powered Elasticsearch & Generative AI combo,
Elastic AI Assistant:
Its open framework allows you to easily connect to the new models to facilitate comparison and adopt domain-specific models for various applications.
It serves as a unified data analytics platform, noticeably minimizing the complexity and cost of data collection, storage, and analysis.
The Elastic AI Assistant lets you create your own prompts to share with your team.
Elastic shows all the data that will be sent to the LLM and allows you to change, redact, or remove it beforehand.
It allows you to provide organizational context to eventually ground each answer in your organization-specific data.
But remember that you’ll need to generate embeddings or vectors to get started with vector search in Elasticsearch.
Elasticsearch & Generative AI: How Elasticsearch Generates Embeddings?
Elasticsearch usually generates embeddings by using the SentenceTransformers framework, which is installed as a Python package. This is the recommended approach because the models available under this framework are free to use, can be installed on your computer, and perform quite well without a GPU.
Here are the exact steps to generate an embedding:
Activate your Python virtual environment.
Execute the “pip install sentence-transformers” command to install the SentenceTransformers framework.
Update your requirements file as one of the best practices by executing the “pip freeze > requirements.txt” command.
Choose and locate your preferred model in the table.
Click the “info” icon to display its details.
Run the given command to download and install the model in your virtual environment:
“from sentence_transformers import SentenceTransformer
model = SentenceTransformer(‘all-MiniLM-L6-v2’)”
Wait for the installation to complete.
Finally, generate the embedding by executing the “embedding = model.encode(‘your source text’)” command.
Consequently, you’ll have an array with all the numbers that constitute the embedding.
Model Selection Guidance
To help you with the model selection, here is what the SentenceTransformers documentation suggests regarding their pre-trained models:
The all-* models are created as general-purpose models and were trained on all available training data which is more than one billion training pairs.
The all-mpnet-base-v2 model offers the best quality.
The all-MiniLM-L6-v2 model is five times faster. Still, it offers good quality.
Note that the length of the resulting embedding will vary based on the model you choose. However, this won’t affect the advanced AI relevance capabilities ESRE offers.
Relevance Ranking in Elasticsearch
Relevance ranking refers to the process of ranking the search results based on their similarity to the search query. It ensures that the most relevant results appear at the top, significantly improving the customer experience.
Here, you’d be amazed to know that Elasticsearch specializes in relevance ranking. Imagine you want to order the search results based on price, time, or any other factors. Elasticsearch makes it possible for you by offering you highly relevant search results in real time.
How Elasticsearch Ranks the Documents?
Elasticsearch ranks the documents by first reducing the set of the candidate documents. It does this by applying a boolean test that only includes the documents that align with the query. Next, it calculates a score for each document based on its level of relevancy with a particular query. Lastly, these scores determine the order of the documents.
It’s good to keep in mind that Elasticsearch uses the BM25 scoring algorithm by default. The Term Frequency (TF), Inverse Document Frequency (IDF), and Field Length determine a document’s score. That’s the basic working of Elasticsearch. You can enhance it by using Generative AI models along with the existing scoring algorithm through OpenAI and Azure OpenAI connectors.
Elasticsearch & Generative AI: Elasticsearch Connector (OpenAI, Azure OpenAI)
An OpenAI connector lets you leverage OpenAI’s LLMs within Kibana. All you’ll need to do is choose an OpenAI model and create an OpenAI API key before you finally configure the connector in Kibana.
Remember to write the name of the model you choose for future reference. Next, create an API key by following the below steps:
Log in to the OpenAI platform.
Navigate to API keys.
Opt for “Create new secret key.”
Set your key’s name.
Choose an OpenAI project.
Set the preferred permissions.
Click “Create secret key,” copy it, and store it safely. (Note that you won’t be able to access it after leaving this screen.
Once you create the API key, here is how you can configure the OpenAI connector:
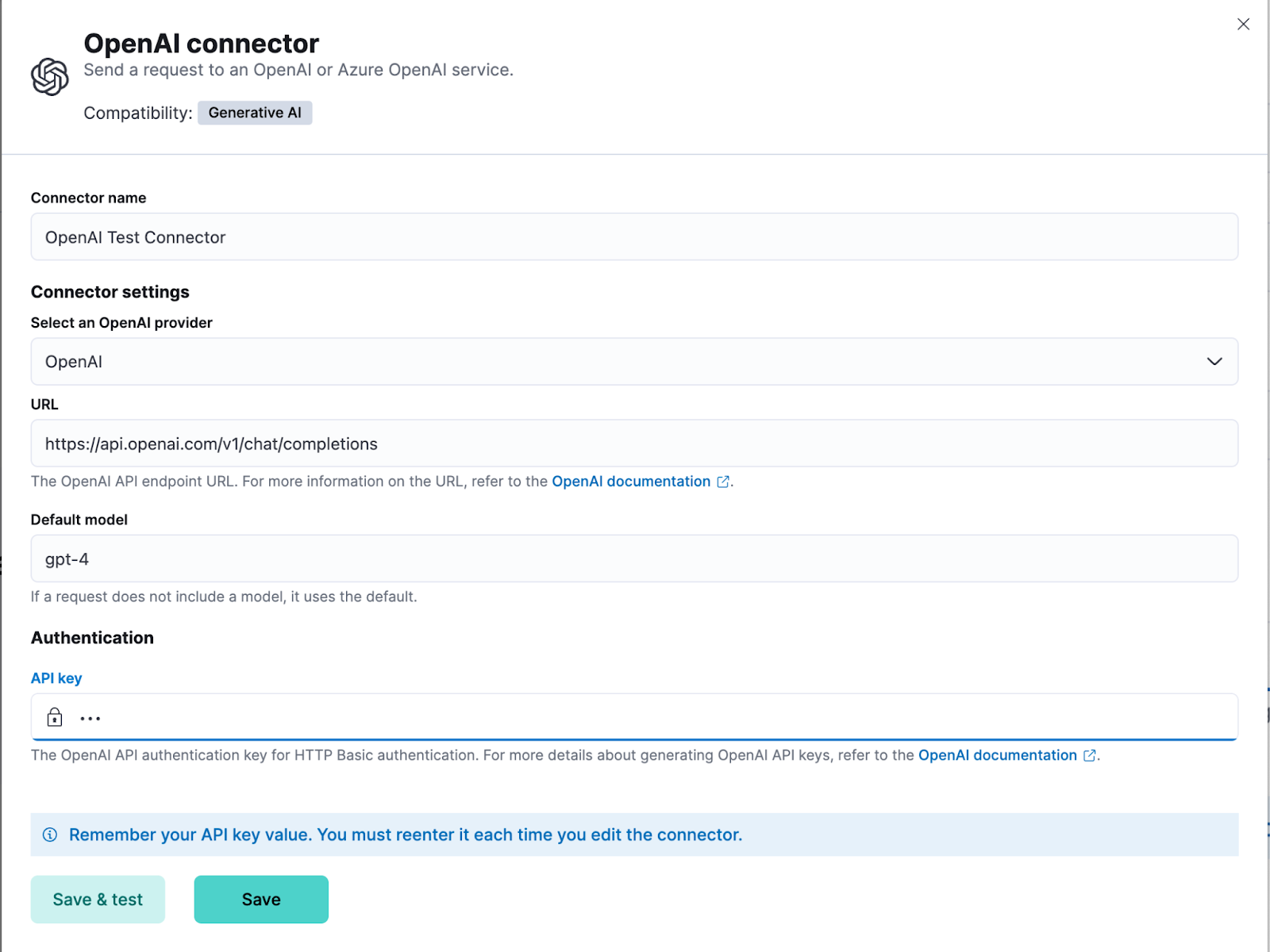
Source Credit: Elastic.co
First of all, log in to Kibana.
Go to Stack Management → Connectors → Create Connector → OpenAI.
Enter a name for your connector.
Choose an appropriate OpenAI provider.
Let the URL field have its default value.
Specify the model that you’d like to use under the Default Model option. (You’ll see this option only when you choose OpenAI as a provider in the fourth step).
Paste the Azure OpenAI or OpenAI API key for authentication.
Say yes to “Save.”
After completing the configuration, watching AI serve you within Kibana would be more satisfying. Try retrieving logs as shown in the following section for a practical experience.
How Elastic Helps to Intelligently Retrieve Logs Using AI?
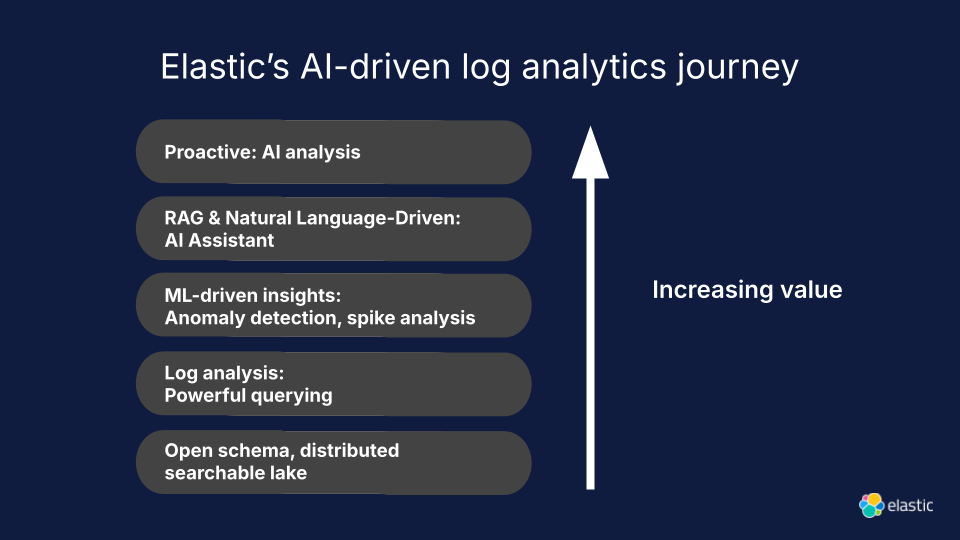
Source Credit: Elastic.co
Elastic helps to intelligently retrieve logs using AI through Elastic Observability. Elastic Observability offers AI-driven log analytics, contextual or related insights, quick identification and resolution of core causes of performance issues, and interactive chat experience as per your proprietary data.
Say that you want to investigate logs from PostgreSQL. You’ll first go to “streams” in Elastic Observability. Next, filter by PostgreSQL. Now, you’ll have all the logs related to PostgreSQL. You can get into a particular log’s details, and ask the Elastic AI Assistant about what that message means and what it relates to. Moreover, you can ask it about the type of query that you can use to get more log information.
Also, here is a real-world example of Elastic Observability’s effectiveness.
“A media company transformed customer experiences with a 3% increase in customer retention, 25% fewer customer calls, and an 85% alleviation in time resolving incidents by using Elastic Observability.” (Elastic)
Conclusion
Finally, you’ve acquired enough knowledge about Elasticsearch & Generative AI. Elasticsearch offers full-text search, offering you relevant search results after reviewing a large amount of data and various documents. On the other hand, Generative AI models can create new content in varied formats based on the data they have been trained with and the one given to them through the prompts.
As both of these search tools have their own capabilities and uniqueness, their combination takes your search experience to another level. Imagine getting accurate and reliable search results in response to your queries instead of generic and doubtful answers. That’s the power of the Elastic AI Assistant, a perfect blend of Elasticsearch & Generative AI.
Here are the key points from this post:
The RAG pattern allows adding an information retrieval system to a Generative AI model.
You can generate embeddings by using the SentenceTransformers framework.
Relevance ranking means ranking the search results according to their similarity to the search query.
An OpenAI connector allows you to leverage OpenAI’s LLMs within Kibana.
Elastic Observability provides AI-driven log analytics.
Do you think that Elasticsearch & Generative AI could have come together earlier? How excited are you to try out the Elastic AI Assistant?